
While machine computation time is taken for granted in an age where computer capacity surrounds us, any work nevertheless takes time on a more granular basis. When the workload increases, it’s critical to understand how the complexity of an algorithm affects the amount of time it takes to accomplish a task. When planning a program, a smart software engineer will think about time complexity. For determining time complexity, Big O notation is the most often used metric. The language we use to communicate about how long an algorithm takes to run is known as Big O notation. It’s the method through which we assess the efficacy of various approaches to an issue. It is expressed in the form O(n), where O stands for “order of magnitude”, and n denotes the task’s difficulty. Using Big O notation, the running time of an algorithm or program can be expressed in terms of the following:
- Rate of increase in runtime: It’s difficult to identify an algorithm’s exact runtime. It is dependent on the CPU speed, as well as what else is operating on the computer. So, rather than discussing the runtime exactly, we use big O notation to discuss how rapidly the runtime rises.
- In comparison to the input: We could describe our speed in seconds if we were directly measuring our runtime. We need to describe our speed in terms of something else because we’re measuring how rapidly our runtime rises. We take the size of the input, which we label “n” in Big O notation. As a result, we may state that the runtime increases “on the order of the size of the input” (O (n)) or “on the order of the square of the size of the input” (O ({n}^{2})).
- When the input increases in size: When n is small, our algorithm may contain steps that appear to be expensive, but as n grows larger, other stages ultimately dominate them. We worry about the item that increases the fastest as the input expands in Big O analysis since everything else is rapidly overtaken when n gets extremely huge.
Fundamental Categories of Complexities and O Notation
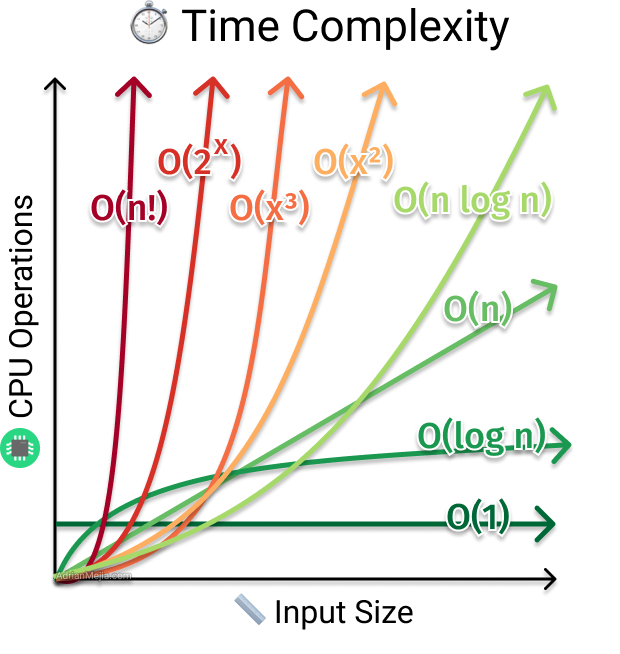
There are many distinct forms of complexity, and this page discusses some of the most fundamental categories and the O notation that represents them. Let’s suppose that the following examples are run in a vacuum, with no background processes, for clarity.
Constant Complexity: O(1)
If an algorithm takes the same amount of time regardless of the number of inputs, it is said to have constant time complexity. Let’s, discuss it with some examples:
Example 1

The above-mentioned program has an O(1) time complexity since it only contains assignment and arithmetic operations, which will all be run only once.
Example 2

Concerning its input, this function executes in O(1) time. The input array could contain one item or 1,000, but this function only requires one step.
Linear Complexity: O(n)
Linear Time Complexity refers to the complexity of an algorithm or program that grows in direct proportion to the quantity of the input data. In circumstances where the algorithm must read its full input sequentially, linear time is the best feasible time complexity. As a result, a lot of effort has gone into finding algorithms that run in linear time or approximately linear time. Let’s, see some examples.
Example 3

We have a control statement in the example above that executes n times. There are other operations like assignment, arithmetic, and a return statement. The time complexity is hence O(n + 3). The constant values become insignificant as n is higher. As a result, if a program just has a control statement, the complexity of assignment, arithmetic, logic, and return statements might be neglected. As a result, the above-mentioned code’s final time complexity is O(n).
Quadratic Complexity: O(N²)
The performance of a quadratic time complexity method is directly proportional to the squared size of the input data collection (think of Linear but squared). This time complexity will appear in our applications anytime we nested numerous iterations within data sets. Take a look at the following example.
Example 4

We’re stacking two loops here. If we have n items in our array, our outer loop will run n times, and our inner loop will run n times for each iteration of the outer loop, totaling {n}^{2} prints. As a result, this function takes O({n}^{2}) time to complete (or “quadratic time”). We must print 100 times if the array has 10 elements. We must print 1000000 times if there are 1000 things.
Exponential Complexity: O(2^n)
An algorithm with exponential time complexity doubles in size with each addition to the input data set. The time complexity begins with a lower level of difficulty and gradually increases till the conclusion. Let’s discuss it with an example.
Example 5

The recursive computation of Fibonacci numbers is an example of an O({2}^{n}) function. The method O({2}^{n}) doubles in size with each addition to the input data set. An O({2}^{n}) function’s growth curve is exponential, with a relatively shallow start and a sudden rise.
Logarithmic Complexity: O(log n)
When the time decreases at a magnitude inversely proportional to N at each successive step in the algorithm, Logarithmic Time Complexity O(log n) happens. This is common in the Binary Search Algorithm. Let’s, discuss it with the help of an example.
Example 6

We’re monitoring numbers in the method above till the array length is passed. We can see, however, that our function will only record values at a specific period. Our method will not have a constant time look-up since we will be repeating a constant time look-up on various sections of the array. It’s also worth noting that our method won’t have a linear time look-up because it won’t go over every index in the array.
Example 7

Using our deck of cards example, we’ll look at another illustration of logarithmic complexity. Let’s suppose that our deck of cards is divided in half, with one pile having the clubs and spades and the other containing the hearts and diamond cards. Now, if I asked you to pick out the 10❤s, you may reasonably assume that the card belongs to the second pile, which also contains the diamonds and hearts cards. You also know that the card should only be found among the hearts, so you split the deck to seek only the hearts. You may reasonably presume that the bottom half of the deck is unimportant because you’ll be looking for the 10❤s (since the deck is already sorted). You can continue splitting the remaining cards until you locate the 10❤s. You don’t have to look through every card to discover it, but it isn’t as simple as picking a card at random. Logarithmic Time Complexity is demonstrated by this example.
Factorial Complexity: O(n!)
If Big O assists us in identifying the worst-case situation for our algorithms, then O(n!) is the worst of the worst. Remember that a factorial is the product of an n-integer sequence. Let’s do it with an example:
Example 8
The factorial of 5, or 5! is:

When computing permutations and combinations, we’ll have to write algorithms with factorial time complexity. In the case of factorial time complexity, our rate of development is almost vertical. It means that our algorithm is taking a long time as well as resources to give results. It’s not that we want to design bad algorithms, but certain issues do not have a simple answer. NP-complete issues are those that have no alternative. In complexity theory, NP-completeness refers to a class of problems for which no known accurate and quick solution exists. Let’s take a look at “real-world” instances to demonstrate this notion.
Example 9

The Traveling Salesman Problem is a typical example of NP-completeness. Assume you’re a traveling salesperson with n cities to visit. Which is the quickest path that stops at each city and brings you back to your starting point? We need to compute every potential route to solve this. Let’s take a look at three cities: Austin, Boston, and Chicago. How many different combinations are there?

This is 3! which means there are six different permutations. If there are three potential beginning places, there are two different paths to the end destination for each starting point. What if we need to go to four different cities? Austin, Boston, Chicago, and Detroit are among the most populous cities in the United States. How many permutations are there? That’s 4! which equals 24 permutations. What about 10 cities? 3628800 is the number. That’s a significant increase and a significant amount of computing processing. For modest inputs, we could simply build an algorithm to brute force a solution, but it doesn’t take long before we reach a point where millions (or more!) of computations are required.